일반적으로 자바에서 얘기하는 두 예외 유형은?
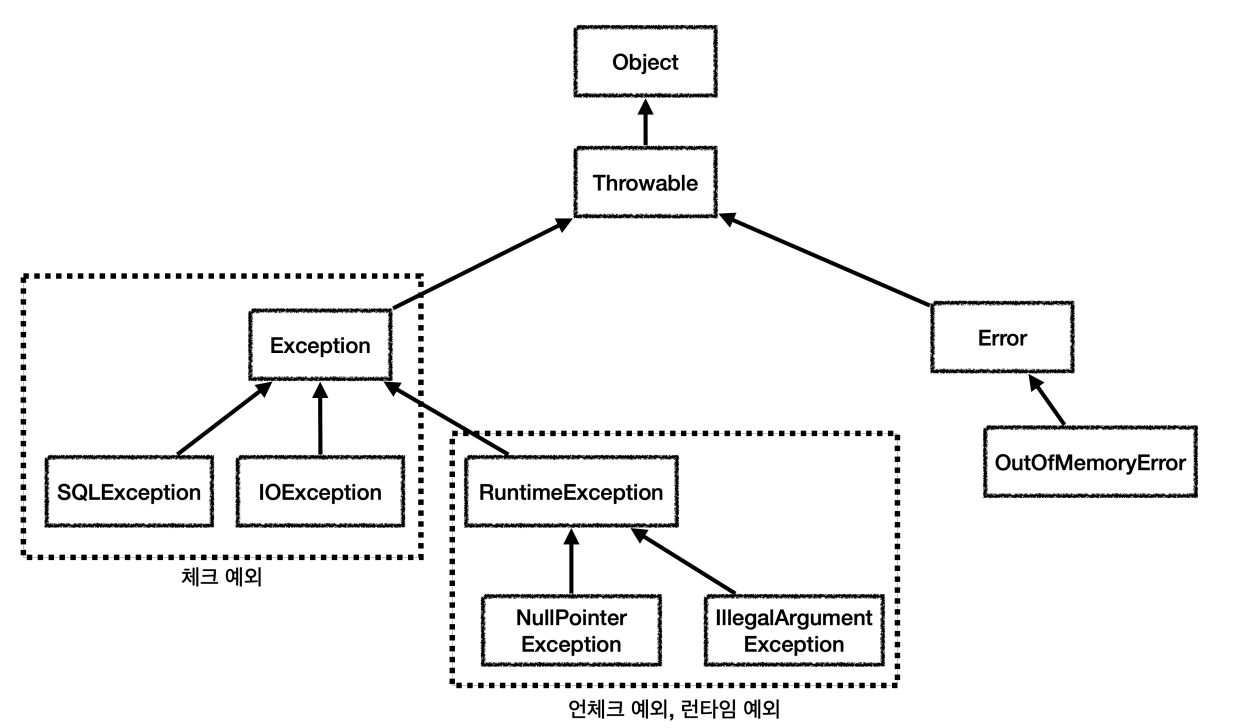
- 체크예외와 언체크 예외(런타임 예외)
- Exception 자손들 중 RuntimeExcpeption만 언체크 예외고 Exception 본인을 포함한 모든 다른 자손들은 체크 예외
체크 예외와 언체크 예외의 차이는?
- 체크 예외
- 개발자가 미리 예상할 수 없는 예외들에 대해 체크한다는 개념으로, 미리 체크를 해야 하기 때문에 이 예외에 대해 처리가 되어 있지 않으면 컴파일 에러가 남
- 미리 체크를 한다는 것은 try ~ catch로 처리를 하거나 throw를 통해 상위에서 처리하도록 하는 방법이 있음.
- 일반적으로 SQLException, IOException, Network 관련 등 코드 외에 외부 자원을 사용하는 등 개발자가 컨트롤할 수 있는 범위 외에서 발생한 문제들은 체크 예외에 들어감
- 언체크 예외
- 언체크 예외는 런타임 예외라고도 불리며 체크 예외와 달리 미리 체크하지 않아도 되기 때문에 try ~ catch나 throw가 없어도 됨.
- 일반적으로 코드가 돌아가다가 잘못된 부분에 대해 우발적으로 발생 가능
체크 예외와 언체크 예외 각각의 장단점은?
| 구분 | 장점 | 단점 |
| 체크 예외 | - 예외를 누락하지 않도록 컴파일러가 강제하므로 안정성을 높임 | - 모든 체크 예외를 처리하거나 던져야 하므로 번거로움 - 신경 쓰고 싶지 않은 예외까지 처리해야 함 |
| 언체크 예외 |
- 처리하고 싶지 않은 예외를 무시할 수 있어 코드 작성이 간편함 - 예외의 의존관계를 참조하지 않아도 됨 |
- 개발자가 예외를 누락할 가능성이 있음 - 컴파일러가 예외 처리 누락을 검출하지 못함 |
- 체크 예외의 경우 예를 들어서 DB 커넥션이 실패한 경우도 체크 예외로 처리를 해줘야 하는데, 이거에 대해 try ~ catch로 묶더라도 근본적인 문제를 해결할 수 있는 방안이 없음.
- throw로 위로 올려도 이거에 대한 방안이 없기 때문에 결국 상위 모든 함수에 throw를 통해 전달해야 하는 번거로움이 생김.
- 언체크 예외는 예외를 개발자가 누락할 가능성이 있기 때문에 런타임 에러에 대해 자세히 문서화를 해서 문제가 생기지 않도록 방지해야 함.
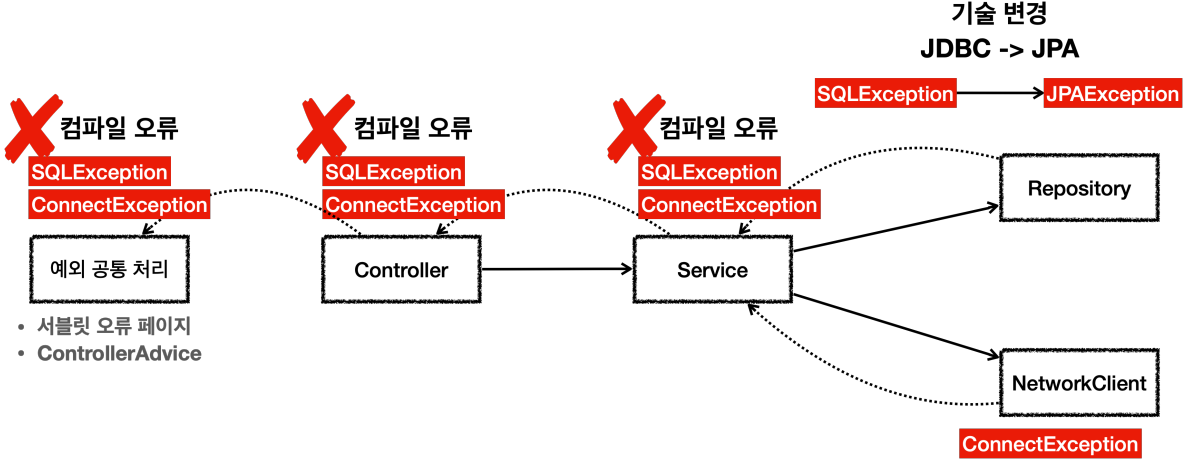
SQLException은 체크 예외인데, 이 예외는 JPA로 넘어가면 JPA관련 에러로 변경이 될 수 있어서, 상위에 있는 다른 함수들은 모두 이 코드를 수정해줘야 하는데, 이러한 문제점들을 어떻게 해결 가능한가?
public void call() {
try {
runSQL();
} catch (SQLException e) {
throw new RuntimeSQLException(e);
}- SQLException이 발생했을 때 이는 체크 예외이기 때문에 체크 예외가 아닌 Runtime 예외로 변경해서 throw를 해주면 해결이 됨.
만약 로그를 출력했는데 마지막 로그 위치만 출력이 되고 그 전의 로그 위치가 출력이 되지 않는다면 그것은 무슨 문제인가?
public void call() {
try {
runSQL();
} catch (SQLException e) {
throw new RuntimeSQLException(); //기존 예외(e) 제외
}
}- 위와 같이 기존 에러가 발생했더라도 RuntimeSQLException() 함수에 parameter를 e를 넣지 않는다면 기존에 발생한 에러 위치는 출력지 되지 않게 됨.
- 따라서 RuntimeSQLException(e) 와 같이 기존 예외의 e를 parameter로 전달해줘야 기존 에러정보까지 함께 전달이 됨.
- 실무에서 이러한 실수로 발생하는 문제가 잦다고 함.
SQL에서 에러가 날 경우 Catch 하여 RuntimeException으로 다시 throw 하려고 하는데, ID 중복과 같은 특정 SQLException에 대한 별도의 처리 방법이 있는가?
if (e.getErrorCode() == 23505) {
throw new MyDuplicateKeyException(e);
}- H2 DB의 경우 DuplicateKey에 에러 코드가 23505로 정의되어 있고, 따라서 위와 같은 코드로 특정 SQLException이 어떤 Exception인지 파악이 가능하며, 그 Exception에 대한 처리 로직을 추가해줄 수 있음.
- 하지만 이는 H2 DB와 Oracle, MySQL 등 각 DB에 따라 에러 코드가 달라서 DB가 달라지면 처리 로직이 달라짐.
특정 SQLException 코드가 DB마다 다른 문제를 어떻게 해결할 수 있는가?
private final SQLExceptionTranslator exTranslator;
this.exTranslator = new SQLErrorCodeSQLExceptionTranslator(dataSource);
...
catch(SQLException e){
throw exTranslator.translate("save", sql, e);
...- SQLExceptionTranslator가 특정 SQLException에 대한 에러 코드를 각 DB에 해당하는 에러코드로 변환해줌.
- new SQLErrorCodeSQLExceptionTranslator(dataSource); 에서 datasource를 넣어주는 이유는, datasource 정보를 넣어줌으로써 어떤 DB인지를 파악해 각 DB에 맞는 에러 코드로 변환해주기 위해서
- sql-error-codes.xml 파일에 각 DB마다 어떠한 에러가 어떠한 에러 코드로 맵핑되어 있는지에 대한 정보가 저장되어 있음
SQLException Translation과 같은 기능이나 connection을 매번 맺고 종료하는 등을 편하게 자동으로 제공해주는 기술을 설명하시오
// Previous Code
public Member save(Member member) {
String sql = "insert into member(member_id, money) values(?, ?)";
Connection con = null;
PreparedStatement pstmt = null;
try {
con = getConnection();
pstmt = con.prepareStatement(sql);
pstmt.setString(1, member.getMemberId());
pstmt.setInt(2, member.getMoney());
pstmt.executeUpdate();
return member;
} catch (SQLException e) {
throw exTranslator.translate("save", sql, e);
} finally {
close(con, pstmt, null);
}
}
// New code
public Member save(Member member) {
String sql = "insert into member(member_id, money) values(?, ?)";
template.update(sql, member.getMemberId(), member.getMoney());
return member;
}- JDBCTemplate과 같은 기술이 그러한 기능을 제공해주며 JDBC가 아니라면 JPA나 Mybatis 템플릿 등의 템플릿이 그 기능을 제공함
- Connection, Statement, ResultSet 등의 리소스 관리와 SQL 예외 처리를 자동으로 처리해줘 개발자는 작업의 핵심 로직에만 집중 가능
'김영한의 스프링 DB 1편' 카테고리의 다른 글
| 김영한의 스프링 DB 1편(트랜잭션) (4) | 2025.01.16 |
|---|---|
| 김영한의 스프링 DB 1편(JDBC) (0) | 2025.01.14 |